Proverbs from China and India (possibly)
(Reposting from G+ for posterity)
I came across this 1907 book by Arthur Guiterman (who was previously encountered here), titled “Betel Nuts: or What They Say in Hindustan”, in which he claims to have collected proverbs and sayings “gleaned in Bengal, in the Punjab, in Rajputana, and even among the mountains of Kashmir and Afghanistan”.
I write “claims”, because the practice was rampant, at the time, to write random things and attribute them to various exotic peoples. Nevertheless, many of these look like genuine proverbs from the region. He writes:
These proverbs, and hundreds like them, are ever in the mouths of the people of Hindustan, giving spice and color to their speech even as the Betel Nut—the chewing-gum of the Orient—spices the breath and reddens the lips of the folks of the bazaars. Many of them are more than proverbs: they are really condensations of shrewd, pithy stories illustrative of native life in its varied phases—stories so well known that the repetition of a couplet containing the point conveys the whole tale to the mind of the hearer. It is literature in shorthand.
This is a good description of the way proverbs and other sayings are used in India. (See Sadāsvāda post on nyāya-s.)
Of the verses in the collection, some are still good sayings (helped by the rhyme), some are recognizable from subhāṣita collections or real Indian proverbs, some are dull in English but evoke the possibility of having been something pithy in the original, and some are interesting only for what they may say about a (possibly fictional) culture that may have had such proverbs.
In a second book, published in 1920 when the first book was out of print, he reproduces these with a few more added (some lightly modified), along with a section titled “Chips of Jade: or What They Say in China”, containing proverbs putatively from China.
Some samples below, from both “Betel Nuts” and “Chips of Jade”. Each verse is independent.
Betel Nuts, or What They Say in Hindustan
God ripes the mangoes,
The Farmer shakes the tree:
God cures the patient,
The Doctor takes the fee.
Now hear the words the Brahman said:
“The Lion’s Mane, the Miser’s Hoard,
The Serpent’s Fang, the Brave Man’s Sword,
Ye may obtain — when they are dead.”
Three were invited — here come Nine!
Water the porridge; all shall dine.
He laughed derision when his Foes
Against him cast, each man, a Stone:
His Friend in anger flung a Rose —
And all the City heard him groan.
They toil not, but decry their bread.
They fight not, they defame the Dead.
The Goat gave up her life; ’twas not enough.
The Eater grumbles that the meat is tough.
A Day or a Minute? a Year or a Moon?—
Now, which does he mean when he says, “Pretty soon!”
Thou lackest, O Shirker,
Though long thou hast prayed?
Know, God’s a Good Worker,
But loves to have Aid.
Buy not, like a hapless Dunce,
Gauds unworth the Keeping.
“Dear,” O Sahib, weeps but once;
“Cheap” is always weeping.
Liars died in Days of Old;
Now, they never catch a Cold!
The Chiefs that Peasants choose by Lot
They will not be afraid of.
The Idol-carver worships not;
He knows what Gods are made of.
The Goat made friends with the Grass and Wheat;
Now what, oh, what may the poor Goat eat?
Smooth Flatterers have done much wrong
For which the World is paying.
If none had praised the Donkey’s Song
He would not still be braying.
Small Ills are the Fountains
Of most of our Groans.
Men trip not on Mountains,
They stumble on Stones.
“My Beard is burning!” one will cry.
Another lights his Pipe thereby.
“My Wisdom aids the World!”— How sweet
That Secret Thought of Great and Small!
The Sea-gull sleeps with Upturned Feet
To catch the Sky when that shall fall.
I hurled the Missile: With Edge unstained
The Shard returned to its Parent Clay;
The Birds, all clamoring, whirred away;
The Sin of Seeking to Kill remained.
“O Allah, take me!” prayed Ram Chunder.
Above him crashed and rolled the thunder.
“Not now!” he cried in fright and sorrow.
“Not now O Lord! — I meant tomorrow!”
[^”Allah” changed to “Shiva” in second book!]
The Tiger came! She slew him
And dragged him from the House
And down the Drain she threw him; —
And yet, she fears a Mouse!
Avoid Suspicion: When you’re walking through
Your Neighbor’s Melon-patch, don’t tie your Shoe.
If You suspect him,
Then Reject him.
If you Select him,
Don’t Suspect him.
A Demon, sick of Single Life,
In Lanka wed a Monkey Wife;
And thence arose, by Heaven’s Grace
(Lal Das declares), the English Race.
“Who cooked this Rice?”
“Not I! — that Worthless Hound!”
“’Tis very nice.”
“Why—yes—I stirred it round!”
Ben Ali, Ram Chunder and Yussuf are tall,
But the Man with the Club is the Lord of them all.
A Queen are you and a Queen am I, —
But who will spread the Clothes to dry?
A Shower of Honey on a Sugar Shed
Is shamed by Speech of Lovers newly wed.
“O Allah,” prays the Cat in hungry Zeal,
“Send Blindness on my Lord, that I may steal!”
“O Allah,” prays the Dog, “endow with Meat
My Lord, who, being filled, shall bid me eat!”
Lal Mir’s Cat is grown too fat
To hunt her Prey and snatch it.
A Mouse she saw and waved her Paw
To bid her Master catch it.
“He has killed a Thousand Men!”
“Ah? he’s Half a Doctor, then.”
The Donkey turns a hungry Eye
Upon the Fields all bare and dry;
Then waxes fat, the Happy Ass,
To think he’s eaten all that Grass!
The Comb was the Bee’s,
But by Man it is eaten.
The Sin was the Flea’s,
But the Bedding is beaten.
I’ve found my Knife, but where are you, O Hound!
When I find you, my Knife can not be found!
[^ Occurs in some Subhashita collection: stone]
The Rains have come! The Rice-blades spring!
The Farmer cares not who is King!
The eager Fish
Repent within the Net.
Young Lovers wish,
And Married Men regret.
Death took him off
But cured his Cough.
My Love departs with Dawning Light,
Mine Eyes are dark with Sorrow.
I pray thee, Lord, make such a Night
That there shall be no Morrow!
The Farmer prays for Rain,
The Washerman for Sun.
If Prayers were not in vain,
The World would be undone.
These Letters Black are Seeds, the which my Pen
In Snow white Furrows diligently sows;
The Harvest shall be reaped by other Men,
But what shall be that Harvest, Heaven knows.
The donkey to the camel said,
“How dainty are your feet!”
The camel to the donkey said,
“Your voice is very sweet!”
[^ occurs somewhere: …aho rūpam…]
My lord, when called “My Lord!” will duly come.
‘Tis thus I keep “my lord” beneath my thumb.
At Men of Deeds are jealous slanders thrown,
As Stones are cast at Fruitful Trees alone.
Four things in Stubbornness all else surpass:
A Child, a King, a Woman and an Ass.
By diverse Yearnings torn and tried.
Poor Men grow ever thinner:
The Bridegroom longs to see the Bride,
The Guests to see the Dinner.
“Yes,” says the Man; “Yes,” says the Woman, too;
And what can Judge, or Priest, or Sultan do?
A Man may greet his Friends with honeyed Tongue,
And yet in Trade be hard and cold as Ice.
The Cat has Gentle Teeth to hold her Young,
But very Different Teeth for catching Mice.
They that challenge Danger, bring
On themselves disastrous Force:
Do not stand Before the King,
Do not stand Behind the Horse.
[^I’ve heard “ಅರಸನ ಮುಂದಿರಬೇಡ, ಕತ್ತೆಯ ಹಿಂದಿರಬೇಡ” but https://kn.wikipedia.org/wiki/ಗಾದೆ / https://kn.wikiquote.org/wiki/ಗಾದೆಗಳು have “ಅರಮನೆಯ ಮುಂದಿರಬೇಡ, ಕುದರೆಯ ಹಿಂದಿರಬೇಡ”.]
The Bitter Gourd I planted where Sago Heaps had lain,
With Treacle-drops and Honey I drenched the Little Hill;
I trained the Leafy Tendrils on rods of Sugar Cane;
But when the Fruit had ripened, alas! ’twas Bitter still!
What Culprit fails to urge the Plea
That there are Others Worse than He?
Chips of Jade, or What They Say in China
Eight Sailors; Seven want to steer.
That Junk won’t come to Port, I fear.
Within the Home where fewer Servants dwell,
With greater Speed the Daily Work is done:
One Man will bring Two Buckets from the Well;
Two Men, between them both, will carry One.
The Starveling Cat maintains the Firm Belief
That every Well-fed Cat must be a Thief.
It somewhat soothes the Bankrupt’s woe
To talk of Debts that Others owe.
Two Friends have I — True Friends, I know;
But which a Deeper Love discloses?
This, brings me Coals in Winter’s Snow,
While That, in Summer, brings me Roses.
Though the Doctor is sure
As his Charges are high.
He whom Medicines cure
Was not Fated to Die.
If Right, though Right without a Flaw
Is _All_ you have, don’t go to Law.
Fear not lest Men say Evil Things of you.
But fear to do the Ill they say you do.
This One Makes a Net,
That One stands and wishes;
Would you like to bet
Which One gets the Fishes?
Words are Wind in Empty Space;
Writing leaves a Lasting Trace.
Defame a Man of Energy, and soon
The Mob will echo, mingling Truth and Lie.
Let one lone Mangy Mongrel bay the Moon,
And all the Village Curs will swell the Cry.
Still leagues on leagues the Great Wall stretches on,
But where has Shi Hwang-ti, who built it, gone?
Search thrice thy Heart and thrice thy Soul again;
Thus shalt thou know the Minds of Other Men.
In Talk he’s a Wonder,
But Small are his Gains.
How loud is the thunder!
How little it Rains!
The Petty Rascal’s Fetters clank;
The Wholesale Robber starts a Bank.
Shall I, grasping, gather Wealth and breed it —
For my Children jealously conserve it?
Should my Sons surpass me, they won’t need it;
Should they not, why then, they won’t deserve it.
The Boy may plan to fly his Kite,
The Man to cut his Hay;
But Old North Wind comes up at night
And blows their Plans away.
Recorded Words are Fetters;
When Angry, don’t write Letters.
You “Nearly Did it”? That’s your loss.
I’ll pay you just the Fare
Due him that rowed me half across
The Stream — and left me there!
The Heron sought to sup his fill
Upon the Clam, who caught his bill
And held him fast, till, nothing loath,
The Hungry Fisher bagged them Both.
Untrained is he that hath not seen
The World’s Rough Face in Sun and Shower,
That hath not shared the Fat and Lean,
That hath not tasted Sweet and Sour,
And known the Foul, but loved the Clean,
And felt the Thorn, yet plucked the Flower.
Fame is the Dew on the Jasmine Stalk,
Fame is the Scream of a passing Hawk,
Fame is the Foam of the Vessel’s Keel,
Fame is a dying Thunder Peal,
Fame is the Scent on the Mountain Moss
Left when the Musk Deer bounds across.
The Arrow’s on the String,
The supple Bow is bent;
My Hand must do that Thing
For which my Life was lent.
When, wrapped in Flame, your Home’s a blackened Shell,
‘Tis growing rather late to Dig a Well.
[^ I think this is in a subhashita collection too]
Your Acres teem with Rice; — but still
A Pint a Day is all you eat.
Your House is wide; the Space you fill
Therein is hardly Seven Feet.
[^ gośatādapi gokṣīraṃ prasthaṃ dhānyaśatādapi / prāsādepi ca khaṭvārdhaṃ śeṣāḥ paravibhūtayaḥ // https://groups.google.com/forum/#!topic/sadaswada/yBw3u03Fqvw%5D
Her Fragrance proved by every Breeze that blows,
What need is there of Words to praise the Rose?
Fish see the Bait alone; and is it stranger
That Men should see the Profit, not the Danger?
Up, Farmer! Toil
While Dawn is hazy!
The Good Brown Soil
Is never lazy.
One Kind Word keeps the Heart aglow
Through Three Long Months of Ice and Snow.
When Drinking Water, bless the Parent Rill;
When Eating, thank the Plow that broke the Clod;
When Donning Garments, praise the Weaver’s Skill;
With every Breath He gives, remember God.
The Monkey jeers; such odd Mistakes
In Weaving Sticks, the Pigeon makes!
But while the Monkey has his Jest,
The Pigeon learns to Build a Nest.
A Word has stolen in and bred a Doubt;
Ten Thousand Oxen cannot drag it out.
Ride within or carry the Sedan,
What’s the difference? — Are you not a Man?
The Monastery near
The Nunnery is set;
There’s nothing wrong or queer
In that, of course — and yet —
A simple puzzle, with a foray into inequivalent expressions
[Needs cleanup… just dumping here for now.]
Mark Jason Dominus tweeted and later blogged about this puzzle:
From the four numbers [6, 6, 5, 2], using only the binary operations [+, -, *, /], form the number 17.
When he tweeted the first time, I thought about it a little bit (while walking from my desk to the restroom or something like that), but forgot about it pretty soon and didn’t give it much further thought. When he posted again, I gave it another serious try, failed, and so gave up and wrote a computer program.
This is what I thought this time.
Idea
Any expression is formed as a binary tree. For example, 28 = 6 + (2 * (5 + 6)) is formed as this binary tree (TODO make a proper diagram with DOT or something):
+
6 *
2 +
5 6
And 8 = (2 + 6) / (6 – 5) is this binary tree:
/
+ -
2 6 6 5
Alternatively, any expression is built up from the 4 given numbers [a, b, c, d] as follows:
Take any two of the numbers and perform any operation on them, and replace the two numbers with the result. Then repeat, until you have only one number, which is the final result.
Thus the above two expressions 28 = 6 + (2 * (5 + 6)) and 8 = (2 + 6) / (6 – 5) can be formed, respectively, as:
- Start with [6, 6, 5, 2]. Replace (5, 6) with 5+6=11 to get [6, 11, 2]. Replace (11, 2) with 11*2=22 to get [6, 22]. Replace (6, 22) with 6+22=28, and that’s your result.
- Start with [6, 6, 5, 2]. Replace (2, 6) with 2+6=8 to get [8, 6, 5]. Replace (6, 5) with 6-5=1 to get [8, 1]. Replace (8, 1) with 8/1=8 and that’s your result.
So my idea was to generate all possible such expressions out of [6, 6, 5, 2], and see if 17 was one of them. (I suspected it may be possible by doing divisions and going via non-integers, but couldn’t see how.)
(In hindsight it seems odd that my first attempt was to answer whether 17 could be generated, rather than how: I guess at this point, despite the author’s assurance that there are no underhanded tricks involved, I still wanted to test whether 17 could be generated in this usual way, if only to ensure that my understanding of the puzzle was correct.)
Multiple ways of understanding
In his wonderful On Proof and Progress in Mathematics, Thurston begins his second section “How do people understand mathematics?” as follows:
This is a very hard question. Understanding is an individual and internal matter that is hard to be fully aware of, hard to understand and often hard to communicate. We can only touch on it lightly here.
People have very different ways of understanding particular pieces of mathematics. To illustrate this, it is best to take an example that practicing mathematicians understand in multiple ways, but that we see our students struggling with. The derivative of a function fits well. The derivative can be thought of as:
- Infinitesimal: the ratio of the infinitesimal change in the value of a function to the infinitesimal change in a function.
- Symbolic: the derivative of
is
, the derivative of
is
, the derivative of
is
, etc.
- Logical:
if and only if for every
there is a
such that when
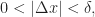
- Geometric: the derivative is the slope of a line tangent to the graph of the function, if the graph has a tangent.
- Rate: the instantaneous speed of
, when
is time.
- Approximation: The derivative of a function is the best linear approximation to the function near a point.
- Microscopic: The derivative of a function is the limit of what you get by looking at it under a microscope of higher and higher power.
This is a list of different ways of thinking about or conceiving of the derivative, rather than a list of different logical definitions. Unless great efforts are made to maintain the tone and flavor of the original human insights, the differences start to evaporate as soon as the mental concepts are translated into precise, formal and explicit definitions.
I can remember absorbing each of these concepts as something new and interesting, and spending a good deal of mental time and effort digesting and practicing with each, reconciling it with the others. I also remember coming back to revisit these different concepts later with added meaning and understanding.
The list continues; there is no reason for it ever to stop. A sample entry further down the list may help illustrate this. We may think we know all there is to say about a certain subject, but new insights are around the corner. Furthermore, one person’s clear mental image is another person’s intimidation:
- The derivative of a real-valued function
in a domain
is the Lagrangian section of the cotangent bundle
that gives the connection form for the unique flat connection on the trivial
-bundle
for which the graph of
These differences are not just a curiosity. Human thinking and understanding do not work on a single track, like a computer with a single central processing unit. Our brains and minds seem to be organized into a variety of separate, powerful facilities. These facilities work together loosely, “talking” to each other at high levels rather than at low levels of organization.

This has been extended on the MathOverflow question Different ways of thinking about the derivative where you can find even more ways of thinking about the derivative. (Two of the interesting pointers are to this discussion on the n-Category Café, and to the book Calculus Unlimited by Marsden and Weinstein, which does calculus using a “method of exhaustion” that does not involve limits. (Its definition of the derivative is also mentioned at the earlier link, as that notion of the derivative closest to [the idea of Eudoxus and Archimedes] of “the tangent line touches the curve, and in the space between the line and the curve, no other straight line can be interposed”, or “the line which touches the curve only once” — this counts as another important way of thinking about the derivative.)
It has also been best extended by Terence Tao, who in an October 2009 blog post on Grothendieck’s definition of a group gave several ways of thinking about a group:
In his wonderful article “On proof and progress in mathematics“, Bill Thurston describes (among many other topics) how one’s understanding of given concept in mathematics (such as that of the derivative) can be vastly enriched by viewing it simultaneously from many subtly different perspectives; in the case of the derivative, he gives seven standard such perspectives (infinitesimal, symbolic, logical, geometric, rate, approximation, microscopic) and then mentions a much later perspective in the sequence (as describing a flat connection for a graph).
One can of course do something similar for many other fundamental notions in mathematics. For instance, the notion of a group
can be thought of in a number of (closely related) ways, such as the following:
- Motivating examples: A group is an abstraction of the operations of addition/subtraction or multiplication/division in arithmetic or linear algebra, or of composition/inversion of transformations.
- Universal algebraic: A group is a set
, a unary inverse operation
, and a binary multiplication operation
obeying the relations (or axioms)
,
,
for all
.
- Symmetric: A group is all the ways in which one can transform a space
to itself while preserving some object or structure
on this space.
- Representation theoretic: A group is identifiable with a collection of transformations on a space
- Presentation theoretic: A group can be generated by a collection of generators subject to some number of relations.
- Topological: A group is the fundamental group
of a connected topological space
.
- Dynamic: A group represents the passage of time (or of some other variable(s) of motion or action) on a (reversible) dynamical system.
- Category theoretic: A group is a category with one object, in which all morphisms have inverses.
- Quantum: A group is the classical limit
of a quantum group.
etc.
One can view a large part of group theory (and related subjects, such as representation theory) as exploring the interconnections between various of these perspectives. As one’s understanding of the subject matures, many of these formerly distinct perspectives slowly merge into a single unified perspective.From a recent talk by Ezra Getzler, I learned a more sophisticated perspective on a group, somewhat analogous to Thurston’s example of a sophisticated perspective on a derivative (and coincidentally, flat connections play a central role in both):
- Sheaf theoretic: A group is identifiable with a (set-valued) sheaf on the category of simplicial complexes such that the morphisms associated to collapses of
-simplices are bijective for
(and merely surjective for
).
The rest of the post elaborates on this understanding.
Again in a Google Buzz post on Jun 9, 2010, Tao posted the following:
Bill Thurston’s “On proof and progress in mathematics” has many nice observations about the nature and practice of modern mathematics. One of them is that for any fundamental concept in mathematics, there is usually no “best” way to define or think about that concept, but instead there is often a family of interrelated and overlapping, but distinct, perspectives on that concept, each of which conveying its own useful intuition and generalisations; often, the combination of all of these perspectives is far greater than the sum of the parts. Thurston illustrates this with the concept of differentiation, to which he lists seven basic perspectives and one more advanced perspective, and hints at dozens more.
But even the most basic of mathematical concepts admit this multiplicity of interpretation and perspective. Consider for instance the operation of addition, that takes two numbers x and y and forms their sum x+y. There are many such ways to interpret this operation:
1. (Disjoint union) x+y is the “size” of the disjoint union X u Y of an object X of size x, and an object Y of size y. (Size is, of course, another concept with many different interpretations: cardinality, volume, mass, length, measure, etc.)
2. (Concatenation) x+y is the size of the object formed by concatenating an object X of size x with an object Y of size y (or by appending Y to X).
3. (Iteration) x+y is formed from x by incrementing it y times.
4. (Superposition) x+y is the “strength” of the superposition of a force (or field, intensity, etc.) of strength x with a force of strength y.
5. (Translation action) x+y is the translation of x by y.
5a. (Translation representation) x+y is the amount of translation or displacement incurred by composing a translation by x with a translation by y.
6. (Algebraic) + is a binary operation on numbers that give it the structure of an additive group (or monoid), with 0 being the additive identity and 1 being the generator of the natural numbers or integers.
7. (Logical) +, when combined with the other basic arithmetic operations, are a family of structures on numbers that obey a set of axioms such as the Peano axioms.
8. (Algorithmic) x+y is the output of the long addition algorithm that takes x and y as input.
9. etc.
These perspectives are all closely related to each other; this is why we are willing to give them all the common name of “addition”, and the common symbol of “+”. Nevertheless there are some slight differences between each perspective. For instance, addition of cardinals is based on perspective 1, while addition of ordinals is based on perspective 2. This distinction becomes apparent once one considers infinite cardinals or ordinals: for instance, in cardinal arithmetic, aleph_0 = 1+ aleph_0 = aleph_0 + 1 = aleph_0 + aleph_0, whereas in ordinal arithmetic, omega = 1+omega < omega+1 < omega + omega.
Transitioning from one perspective to another is often a necessary first conceptual step when the time comes to generalise the concept. As a child, addition of natural numbers is usually taught initially by using perspective 1 or 3, but to generalise to addition of integers, one must first switch to a perspective such as 4, 5, or 5a; similar conceptual shifts are needed when one then turns to addition of rationals, real numbers, complex numbers, residue classes, functions, matrices, elements of abstract additive groups, nonstandard number systems, etc. Eventually, one internalises all of the perspectives (and their inter-relationships) simultaneously, and then becomes comfortable with the addition concept in a very broad set of contexts; but it can be more of a struggle to do so when one has grasped only a subset of the possible ways of thinking about addition.
In many situations, the various perspectives of a concept are either completely equivalent to each other, or close enough to equivalent that one can safely “abuse notation” by identifying them together. But occasionally, one of the equivalences breaks down, and then it becomes useful to maintain a careful distinction between two perspectives that are almost, but not quite, compatible. Consider for instance the following ways of interpreting the operation of exponentiation x^y of two numbers x, y:
1. (Combinatorial) x^y is the number of ways to make y independent choices, each of which chooses from x alternatives.
2. (Set theoretic) x^y is the size of the space of functions from a set Y of size y to a set X of size x.
3. (Geometric) x^y is the volume (or measure) of a y-dimensional cube (or hypercube) whose sidelength is x.
4. (Iteration) x^y is the operation of starting at 1 and multiplying by x y times.
5. (Homomorphism) y → x^y is the continuous homomorphism from the domain of y (with the additive group structure) to the range of x^y (with the multiplicative structure) that maps 1 to x.
6. (Algebraic) ^ is the operation that obeys the laws of exponentiation in algebra.
7. (Log-exponential) x^y is exp( y log x ). (This raises the question of how to interpret exp and log, and again there are multiple perspectives for each…)
8. (Complex-analytic) Complex exponentiation is the analytic continuation of real exponentiation.
9. (Computational) x^y is whatever my calculator or computer outputs when it is asked to evaluate x^y.
10. etc.
Again, these interpretations are usually compatible with each other, but there are some key exceptions. For instance, the quantity 0^0 would be equal to zero [ed: I think this should be one —S] using some of these interpretations, but would be undefined in others. The quantity 4^{1/2} would be equal to 2 in some interpretations, be undefined in others, and be equal to the multivalued expression +-2 (or to depend on a choice of branch) in yet further interpretations. And quantities such as i^i are sufficiently problematic that it is usually best to try to avoid exponentiation of one arbitrary complex number by another arbitrary complex number unless one knows exactly what one is doing. In such situations, it is best not to think about a single, one-size-fits-all notion of a concept such as exponentiation, but instead be aware of the context one is in (e.g. is one raising a complex number to an integer power? A positive real to a complex power? A complex number to a fractional power? etc.) and to know which interpretations are most natural for that context, as this will help protect against making errors when manipulating expressions involving exponentiation.
It is also quite instructive to build one’s own list of interpretations for various basic concepts, analogously to those above (or Thurston’s example). Some good examples of concepts to try this on include “multiplication”, “integration”, “function”, “measure”, “solution”, “space”, “size”, “distance”, “curvature”, “number”, “convergence”, “probability” or “smoothness”. See also my blog post below in which the concept of a “group” is considered.
I plan to collect more such “different ways of thinking about the same (mathematical) thing” in this post, as I encounter them.
The Pandit (काशीविद्यासुधानिधिः)
The Pandit (काशीविद्यासुधानिधिः)
A Monthly Journal, of the Benares College, devoted to Sanskrit Literature
This was a journal that ran from 1866 to 1920, and some issues are available online. “The Benares College” in its title is what was the first college in the city (established 1791), later renamed the Government Sanskrit College, Varanasi, and now the Sampurnanand Sanskrit University.
There are some interesting things in there. From a cursory look, it’s mainly editions of Sanskrit works (Kavya, Mimamsa, Sankhya, Nyaya, Vedanta, Vyakarana, etc.) and translations of some, along with the occasional harsh review of a recent work (printed anonymously of course), but also contains, among other things, (partial?) translations into Sanskrit of John Locke’s An Essay Concerning Human Understanding and Bishop Berkeley’s A Treatise Concerning the Principles of Human Knowledge. Also some hilarious (and quite valid) complaints about miscommunication between English Orientalists and traditional pandits, with their different education systems and different notions of what topics are simple and what are advanced.
The journal’s motto:
श्रीमद्विजयिनीदेवीपाठशालोदयोदितः । प्राच्यप्रतीच्यवाक्पूर्वापरपक्षद्वयान्वितः ॥
अङ्करश्मिः स्फुटयतु काशीविद्यासुधानिधिः । प्राचीनार्यजनप्रज्ञाविलासकुमुदोत्करान् ॥
The metadata is terrible: there’s only an index of sorts at the end of the whole volume; each issue of the journal carries no table of contents (or if it did, they have been ripped out when binding each (June to May) year’s issues into volumes). Authorship information is scarce. Some translations have been abandoned. (I arrived at this journal looking at Volume 9 where an English translation of Kedārabhaṭṭa’s Vṛtta-ratnākara is begun, carried into three chapters (published in alternate issues), left with a “to be continued” as usual, except there’s no mention of it in succeeding issues.) Still, a lot of interesting stuff in there.
Among the British contributors/editors of the journal were Ralph T. H. Griffith (who translated the Ramayana into English verse: there are advertisements for the translation in these volumes) and James R. Ballantyne (previously encountered as the author of Iṅglaṇḍīya-bhāṣā-vyākaraṇam a book on English grammar written in Sanskrit: he seems to have also been an ardent promoter of Christianity, but also an enthusiastic worker for more dialogue between the pandits and the Western scholars), each of whom served as the principal of the college. (Later principals of the college include Ganganath Jha and Gopinath Kaviraj.) Among the Indian contributors to the journal are Vitthala Shastri, who in 1852 appears to have written a Sanskrit commentary on Francis Bacon’s _Novum Organum,_ (I think it’s this, but see also the preface of this book for context) Bapudeva Sastri, and others: probably the contributors were all faculty of the college; consider the 1853 list of faculty here (Also note the relative salaries!)
Had previously encountered a mention of this magazine in this book (post).
[Edit, added 2020-12-05: Here’s an article by Ashok Aklujkar that lists the works that were published in The Pandit.]
The issues I could find—and I searched quite thoroughly I think—are below. Preferably, someone needs to download from Google Books and re-upload to the Internet Archive, as books on Google Books have an occasional tendency to disappear (or get locked US-only).
[Edit, added 2020-12-09: Some scans by eGangotri, independent of the scanning by Google Books below, have recently been uploaded to the Internet Archive: see here.]
https://books.google.com/books?id=Z71EAAAAcAAJ 1866 Vol 1 (1 – 12)
https://books.google.com/books?id=ESgJAAAAQAAJ 1866 vol 1 (1 – 12)
https://books.google.com/books?id=Sr8IAAAAQAAJ 1866 Vol 1 (1 – 12)
https://books.google.com/books?id=JAspAAAAYAAJ 1866 vol 1-3 (1 – 36)
https://books.google.com/books?id=Y78IAAAAQAAJ 1867 Vol 2 (13 – 24)
https://books.google.com/books?id=JigJAAAAQAAJ 1867 Vol 2 (13 – 24)
https://books.google.com/books?id=cL1EAAAAcAAJ 1867 Vol 2 (13 – 24)
https://books.google.com/books?id=g78IAAAAQAAJ 1868 Vol 3 (25 – 36)
https://books.google.com/books?id=eL1EAAAAcAAJ 1868 Vol 3 (25 – 36)
https://books.google.com/books?id=OSgJAAAAQAAJ 1868 Vol 3 (25 – 36)
https://books.google.com/books?id=m78IAAAAQAAJ 1869 vol 4 (37 – 48)
https://books.google.com/books?id=WygJAAAAQAAJ 1869 Vol 4 (37 – 48)
https://books.google.com/books?id=g71EAAAAcAAJ 1869 vol 4 (37 – 48)
https://books.google.com/books?id=vr8IAAAAQAAJ 1870 vol 5 (49 – 60)
https://books.google.com/books?id=eCgJAAAAQAAJ 1870 vol 5 (49 – 60)
https://books.google.com/books?id=24dSAAAAcAAJ 1870 vol 5 (49 – 60)
https://books.google.com/books?id=0b8IAAAAQAAJ 1871 Vol 6 (61 – 72)
https://books.google.com/books?id=nigJAAAAQAAJ 1871 vol 6 (61 – 72)
https://books.google.com/books?id=5YdSAAAAcAAJ 1871 vol 6 (61 – 72)
https://books.google.com/books?id=878IAAAAQAAJ 1872 Vol 7 (73 – 84)
https://books.google.com/books?id=uCgJAAAAQAAJ 1872 Vol 7 (73 – 84)
https://books.google.com/books?id=TrZUAAAAcAAJ 1872 vol 7 (73 – 84)
https://books.google.com/books?id=6ygJAAAAQAAJ 1873 vol 8 (85 – 96)
https://books.google.com/books?id=ASkJAAAAQAAJ 1874 vol 9 (97 – 108)
https://books.google.com/books?id=KMAIAAAAQAAJ 1874 vol 9 (97 – 108)
https://books.google.com/books?id=ICkJAAAAQAAJ 1875 Vol 10 (109 – 120)
https://books.google.com/books?id=CcAIAAAAQAAJ 1875 vol 10 (109 – 120)
[New series]
https://books.google.com/books?id=jHxFAQAAIAAJ 1876 vol 1
https://books.google.com/books?id=A_lSAAAAYAAJ 1877 vol 2
https://books.google.com/books?id=M31FAQAAIAAJ 1877 vol 2
https://books.google.com/books?id=ZQspAAAAYAAJ 1877 vol 2
https://books.google.com/books?id=rgspAAAAYAAJ 1879 vol 3
https://books.google.com/books?id=w31FAQAAIAAJ 1879 vol 3
https://books.google.com/books?id=EA0pAAAAYAAJ 1882 Vol 4
https://books.google.com/books?id=Pn5FAQAAIAAJ 1882 vol 4
https://books.google.com/books?id=gzoJAAAAQAAJ 1882 vol 4
https://books.google.com/books?id=XA0pAAAAYAAJ 1883 Vol 5
https://books.google.com/books?id=jikJAAAAQAAJ 1883 Vol 5
https://books.google.com/books?id=3X5FAQAAIAAJ 1883 vol 5
https://books.google.com/books?id=zSkJAAAAQAAJ 1884 vol 6
https://books.google.com/books?id=vQ0pAAAAYAAJ 1885 vol 7
https://books.google.com/books?id=Oi8JAAAAQAAJ 1885 vol 7
https://books.google.com/books?id=FQ4pAAAAYAAJ 1886 Vol 8
https://books.google.com/books?id=JwopAAAAYAAJ 1887 vol 9
https://books.google.com/books?id=fQ4pAAAAYAAJ 1888 Vol 10
https://books.google.com/books?id=gAopAAAAYAAJ 1890 vol 12
https://books.google.com/books?id=2wopAAAAYAAJ 1891 vol 13
https://books.google.com/books?id=LwspAAAAYAAJ 1892 vol 14
https://books.google.com/books?id=pAspAAAAYAAJ 1895 Vol 17
https://books.google.com/books?id=wdc9AQAAMAAJ 1895 vol 17
https://books.google.com/books?id=BAwpAAAAYAAJ 1896 Vol 18
https://books.google.com/books?id=UwwpAAAAYAAJ 1897 vol 19
https://books.google.com/books?id=1wwpAAAAYAAJ 1898 Vol 20
https://books.google.com/books?id=1g0pAAAAYAAJ 1899 Vol 21
https://books.google.com/books?id=iBNAAQAAMAAJ 1899 Vol 21
https://books.google.com/books?id=Xg4pAAAAYAAJ 1900 Vol 22
https://books.google.com/books?id=MhApAAAAYAAJ 1901 Vol 23
https://books.google.com/books?id=4w4pAAAAYAAJ 1902 Vol 24
https://books.google.com/books?id=Tw8pAAAAYAAJ 1904 Vol 25
https://books.google.com/books?id=vw8pAAAAYAAJ 1905 Vol 27
https://books.google.com/books?id=iBApAAAAYAAJ 1907 vol 29
https://books.google.com/books?id=bQ0pAAAAYAAJ 1908 Vol 30
https://books.google.com/books?id=Bv1SAAAAYAAJ 1908 Vol 30
https://books.google.com/books?id=LNA9AQAAMAAJ 1911 Vol 33 Snippet View
https://books.google.com/books?id=ctA9AQAAMAAJ 1912 Vol 34 Snippet View
https://books.google.com/books?id=3dA9AQAAMAAJ 1913 Vol 35 Snippet View
https://books.google.com/books?id=a9E9AQAAMAAJ 1916 Vol 38 Snippet View
https://books.google.com/books?id=N9E9AQAAMAAJ 1916 Vol 37 Snippet View
Also on HathiTrust:
https://catalog.hathitrust.org/Record/008634393
c.1 v.3 1868
v. 2 (1878)
c.1 n.s v.17 1895
c.1 n.s v.21 1899
v. 30 (1908)
https://catalog.hathitrust.org/Record/009658676
ser.2 v.1 (1876-77)
ser.2 v.2 (1877-78)
ser.2 v.3 (1878-79)
ser.2 v.4 (1882)
ser.2 v.5 (1883)
https://catalog.hathitrust.org/Record/100339588
v.1-3 (1866-1869)
n.s.:v.2 (1877/1878)
n.s.:v.3 (1878/1879)
n.s.:v.4 (1882)
n.s.:v.5 (1883)
n.s.:v.7 (1885)
n.s.:v.8 (1886)
n.s.:v.9 (1887)
n.s.:v.10 (1888)
n.s.:v.12 (1890)
n.s.:v.13 (1891)
n.s.:v.14 (1892)
n.s.:v.17 (1895)
n.s.:v.18 (1896)
n.s.:v.19 (1897)
n.s.:v.20 (1898)
n.s.:v.21 (1899)
n.s.:v.22 (1900)
n.s.:v.23 (1901)
n.s.:v.24 (1902)
n.s.:v.25 (1903)
n.s.:v.27 (1905)
n.s.:v.29 (1907)
n.s.:v.30 (1908)
The same in every country
(TODO: Learn and elaborate more on their respective histories and goals.)
The formula
(reminded via this post), a special case at 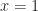
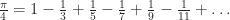
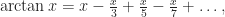
was found by Leibniz in 1673, while he was trying to find the area (“quadrature”) of a circle, and he had as prior work the ideas of Pascal on infinitesimal triangles, and that of Mercator on the area of the hyperbola 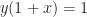
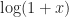
Leibniz did not know that this series had already been discovered earlier in 1671 by the short-lived mathematician James Gregory in Scotland. Gregory too had encountered Mercator’s infinite series 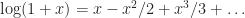
Neither of them knew that the series had already been found two centuries earlier by Mādhava (1340–1425) in India (as known through the quotations of Nīlakaṇṭha c.1500), working in a completely different mathematical culture whose goals and practices were very different. The logarithm function doesn’t seem to have been known, let alone an infinite series for it, though a calculus of finite differences for interpolation for trigonometric functions seems to have been ahead of Europe by centuries (starting all the way back with Āryabhaṭa in c. 500 and more clearly stated by Bhāskara II in 1150). Using a different approach (based on the arc of a circle) and geometric series and sums-of-powers, Mādhava (or the mathematicians of the Kerala tradition) arrived at the same formula.
[The above is based on The Discovery of the Series Formula for π by Leibniz, Gregory and Nilakantha by Ranjay Roy (1991).]
This startling universality of mathematics across different cultures is what David Mumford remarks on, in Why I am a Platonist:
As Littlewood said to Hardy, the Greek mathematicians spoke a language modern mathematicians can understand, they were not clever schoolboys but were “fellows of a different college”. They were working and thinking the same way as Hardy and Littlewood. There is nothing whatsoever that needs to be adjusted to compensate for their living in a different time and place, in a different culture, with a different language and education from us. We are all understanding the same abstract mathematical set of ideas and seeing the same relationships.
The same thought was also expressed by Mean Girls:
The generating function for Smirnov words (or: time until k consecutive results are the same)
1. Alphabet
Suppose we have an alphabet 


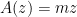

2. Words
Let 
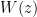
2.1.
We have
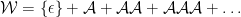
so its generating function is
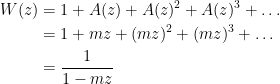
2.2.
To put it differently, in the symbolic framework, we have 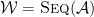
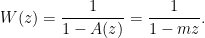
2.3.
We could have arrived at this with direct counting: the number of words of length 


3. Smirnov words
Next, let 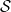
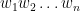



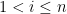
3.1.
For any word in 
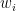
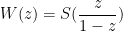
which implicitly gives the generating function 
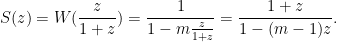
3.2.
Alternatively, consider in an arbitrary word the first occurrence of a pair of repeated letters. Either this doesn’t happen at all (the word is a Smirnov word), or else, if it happens at position 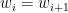

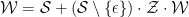
or in terms of generating functions
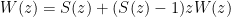
giving
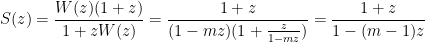
3.3.
A minor variant is to again pick an arbitrary word and consider its first pair of repeated letters, happening (if it does) at positions 
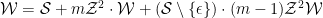
and corresponding generating function
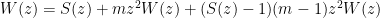
so

which is the same as before after we cancel the 
3.4.
We could have arrived at this result with direct counting. For 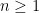
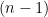
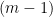
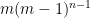
again giving
4. Words with bounded runs
We can now generalize. Let 

4.1.
To get a word in
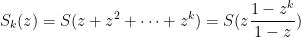
so
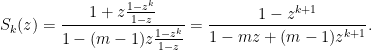
4.2.
Pick any arbitrary word, and consider its first occurrence of a run of 
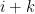
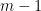
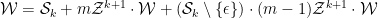
or in terms of generating functions
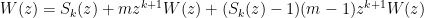
so
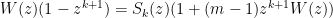
giving
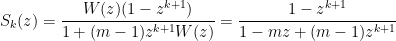
4.3.
Arriving at this via direct counting seems hard.
5. Words that stop at a long run
Now consider words in which we “stop” as soon we see 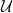
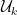
5.1.
We get any word in 
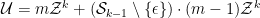
and
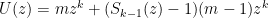
which gives
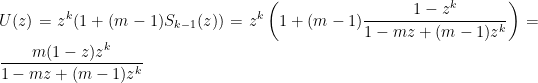
5.2.
Alternatively, we can decompose any word by looking for its first run of
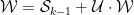
and
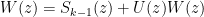
so
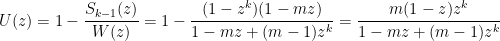
6. Probability
Finally we arrive at the motivation: suppose we keep appending a random letter from the alphabet, until we encounter the same letter 
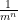
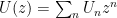


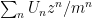
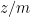
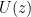
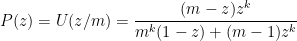
In principle, this probability generating function tells us everything about the distribution of the length of the word. For example, its expected length is
![\displaystyle \mathop{E}[X] = P'(1) = \frac{m^k - 1}{m - 1}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7BE%7D%5BX%5D+%3D+P%27%281%29+%3D+%5Cfrac%7Bm%5Ek+-+1%7D%7Bm+-+1%7D&bg=ffffff&fg=000000&s=0&c=20201002)
(See this question on Quora for other powerful ways of finding this expected value directly.)
We can also find its variance, as
![\displaystyle \mathop{Var}[X] = P''(1) + P'(1) - P'(1)^2 = \frac{m^{2k} - (2k-1)(m-1)m^k - m}{(m-1)^2}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7BVar%7D%5BX%5D+%3D+P%27%27%281%29+%2B+P%27%281%29+-+P%27%281%29%5E2+%3D+%5Cfrac%7Bm%5E%7B2k%7D+-+%282k-1%29%28m-1%29m%5Ek+-+m%7D%7B%28m-1%29%5E2%7D&bg=ffffff&fg=000000&s=0&c=20201002)
This variance is really too large to be useful, so what we would really like, is the shape of the distribution… to be continued.
Converting a data URL (aka data URI) to an image on the commandline (Mac OS X)
This is trivial, but was awfully hard to find via Google Search. Eventually had to give up and actually think about it. :-)
So, a data-URI looks something like the following:
data:image/png;base64,[and a stream of base64 characters here]
The part after the comma is literally the contents of the file (image or whatever), encoded in base64, so all you need to do is run base64 --decode on that part.
For example, with the whole data URL copied to the clipboard, I can do:
pbpaste | sed -e 's#data:image/png;base64,##' | base64 --decode > out.png
to get it into a png file.
Using Stellarium to make an animation / video
(I don’t have a solution yet.)
I just wanted to show what the sky looks like over the course of a week.
On a Mac with Stellarium installed, I ran the following
/Applications/Stellarium.app/Contents/MacOS/stellarium --startup-script stellarium.ssc
with the following stellarium.ssc:
// -*- mode: javascript -*-
core.clear('natural'); // "atmosphere, landscape, no lines, labels or markers"
core.wait(5);
core.setObserverLocation('Ujjain, India');
core.setDate('1986-08-15T05:30:00', 'utc');
core.wait(5);
for (var i = 0; i < 2 * 24 * 7; i += 1) {
core.setDate('+30 minutes');
core.wait(0.5);
core.screenshot('uj');
core.wait(0.5);
}
core.wait(10);
core.quitStellarium();
It took a while (some 10–15 minutes) and created those 336 images in ~/Pictures/Stellarium/uj*, occupying a total size of about 550 MB. This seems a start, but Imagemagick etc. seem to choke on creating a GIF from such large data.
Giving up for now; would like to come back in future and figure out something better, that results in a smaller GIF.
Science
Is hard.
Just dumping some links here for now:
Feynman on “cargo cult science”: http://www.lhup.edu/~DSIMANEK/cargocul.htm
Feynman on “what is science”: http://www.fotuva.org/feynman/what_is_science.html
Ioannidis, Why Most Published Research Findings Are False: http://journals.plos.org/plosmedicine/article?id=10.1371/journal.pmed.0020124
On how subtle it is: http://slatestarcodex.com/2014/04/28/the-control-group-is-out-of-control/
Reinhart, http://www.statisticsdonewrong.com
http://www.nytimes.com/2012/04/17/science/rise-in-scientific-journal-retractions-prompts-calls-for-reform.html?pagewanted=all
https://fivethirtyeight.com/features/science-isnt-broken/
Another well argued summary: http://www.firstthings.com/article/2016/05/scientific-regress
The state of static analysis on Python
Here is a program that fails with UnboundLocalError three out of four times:
"""Module to demonstrate an error."""
import random
def zero_or_one():
"""Returns either 0 or 1 with equal probability."""
return random.choice([0, 1])
def main():
"""Function to demonstrate an error."""
if zero_or_one():
first = 42
for _ in range(zero_or_one()):
second = 42
print first, second
if __name__ == '__main__':
main()
Note that line 15 uses the variables first and second, which are defined only if zero_or_one() returned 1 both times.
(Condensed from a real bug where, because of additional indentation, a variable assignment happened as the last line inside a loop, instead of the first line after it.)
I know of three tools that are popular: pychecker, pyflakes, and pylint. None of them say a single thing about this program. It is questionable whether ever (and if so, how often) code like the above is what the programmer intended.
The first of these, pychecker, is not on pip, and requires you to download a file from Sourceforge and run “python setup.py install”. Anyway, this is the output from the three programs:
/tmp% pychecker test.py Processing module test (test.py)... Warnings... None /tmp% pyflakes test.py /tmp% pylint test.py No config file found, using default configuration Report ====== 12 statements analysed. Statistics by type ------------------ +---------+-------+-----------+-----------+------------+---------+ |type |number |old number |difference |%documented |%badname | +=========+=======+===========+===========+============+=========+ |module |1 |1 |= |100.00 |0.00 | +---------+-------+-----------+-----------+------------+---------+ |class |0 |0 |= |0 |0 | +---------+-------+-----------+-----------+------------+---------+ |method |0 |0 |= |0 |0 | +---------+-------+-----------+-----------+------------+---------+ |function |2 |2 |= |100.00 |0.00 | +---------+-------+-----------+-----------+------------+---------+ Raw metrics ----------- +----------+-------+------+---------+-----------+ |type |number |% |previous |difference | +==========+=======+======+=========+===========+ |code |11 |73.33 |11 |= | +----------+-------+------+---------+-----------+ |docstring |3 |20.00 |3 |= | +----------+-------+------+---------+-----------+ |comment |0 |0.00 |0 |= | +----------+-------+------+---------+-----------+ |empty |1 |6.67 |1 |= | +----------+-------+------+---------+-----------+ Duplication ----------- +-------------------------+------+---------+-----------+ | |now |previous |difference | +=========================+======+=========+===========+ |nb duplicated lines |0 |0 |= | +-------------------------+------+---------+-----------+ |percent duplicated lines |0.000 |0.000 |= | +-------------------------+------+---------+-----------+ Messages by category -------------------- +-----------+-------+---------+-----------+ |type |number |previous |difference | +===========+=======+=========+===========+ |convention |0 |0 |= | +-----------+-------+---------+-----------+ |refactor |0 |0 |= | +-----------+-------+---------+-----------+ |warning |0 |0 |= | +-----------+-------+---------+-----------+ |error |0 |0 |= | +-----------+-------+---------+-----------+ Global evaluation ----------------- Your code has been rated at 10.00/10 (previous run: 10.00/10, +0.00) /tmp%
Bhavabhuti on finding a reader
Bhavabhūti, the 8th-century author of the very moving play Uttara-rāma-carita, has in one of his other works these lines, any author’s consolation that even if your work receives not enough praise today, someday the right sort of reader will come along, who will derive great joy or meaning from it.
ये नाम केचिदिह नः प्रथयन्त्यवज्ञां जानन्ति ते किमपि तान्प्रति नैष यत्नः । उत्पत्स्यते तु मम कोऽपि समानधर्मा कालो ह्ययं निरवधिर्विपुला च पृथ्वी ॥ye nāma kecit iha naḥ prathayanti avajñām
jānanti te kim api tān prati na eṣa yatnaḥ |
utpatsyate tu mama ko api samāna-dharmā
kālo hi ayaṃ niravadhiḥ vipulā ca pṛthvī ||Those who deride or ignore my work —
let them know: my efforts are not for them.
There will come along someone who shares my spirit:
the world is vast, and time endless.
This verse has become a favourite of many. It appears already in the first known anthology of Sanskrit verses (subhāṣita-collection), Vidyākara’s Subhāṣita-ratna-koṣa. (It’s numbered 1731 (= 50.34) in the edition by Kosambi and Gokhale, and translated by Ingalls.) Ingalls writes and translates (1965):
Of special interest are the verses of Dharmakīrti and Bhavabhūti, two of India’s most original writers, which speak of the scorn and lack of understanding which the writings of those authors found among contemporaries. To such disappointment Dharmakīrti replies with bitterness (1726, 1729), Bhavabhūti with the unreasoning hope of a romantic (1731). If the souls of men could enjoy their posthumous fame the one would now see his works admired even far beyond India, the other would see his romantic hope fulfilled.
Those who scorn me in this world
have doubtless special wisdom,
so my writings are not made for them;
but are rather with the thought that some day will be born,
since time is endless and the world is wide,
one whose nature is the same as mine.
A translation of this verse is also included in A. N. D. Haksar’s A Treasury of Sanskrit Poetry in English Translation (2002):
The Proud Poet
Are there any around who mock my verses?
They ought to know I don’t write for them.
Someone somewhere sometime will understand.
Time has no end. The world is big.
— translated by V. N. Misra, L. Nathan and S. Vatsyayan [The Indian Poetic Tradition, 1993]
Andrew Schelling has written of it in Manoa, Volume 25, Issue 2, 2013:
Critics scoff
at my work
and declare their contempt—
no doubt they’ve got
their own little wisdom.
I write nothing for them.
But because time is
endless and our planet
vast, I write these
poems for a person
who will one day be born
with my sort of heart.“Criticism is for poets as ornithology is for the birds,” wrote John Cage. Bhavabhūti has scant doubt that future generations will honor his work. The reader who will arise, utpalsyate [sic], is somebody of the same faith, heart, or discipline, samānadharmā.
Just now also found it on the internet, here (2014) (misattributed to Bhartṛhari):
There are those who
treat my work with
studied indifference.
Maybe they know something,
but I’m not writing for them.
Someone will come around
who feels the way I do.
Time, after all, is limitless,
and fortune spreads far.
Finally, in Sadāsvada, written by my friend Mohan with some comments from me, this was included in one of our our very first posts (2012):
In his play Mālatīmādhava, he makes a point that deserves to be the leading light of anyone wishing to do something of value and
isput off by discouragement. Standing beside the words attributed to Gandhi (“First they ignore you, then they laugh at you, then they fight you, then you win.”) and Teddy Roosevelt (“It is not the critic who counts…”), Bhavabhūti’s confidence in the future stands resplendent:“They who disparage my work should know that it’s not for them that I did it. One day, there will arise someone who will truly know me: this world is vast, and time infinite.”
It is not the critic who counts; not the man who points out how the strong man stumbles, or where the doer of deeds could have done them better. The credit belongs to the man who is actually in the arena, whose face is marred by dust and sweat and blood; who strives valiantly; who errs, who comes short again and again, because there is no effort without error and shortcoming; but who does actually strive to do the deeds; who knows great enthusiasms, the great devotions; who spends himself in a worthy cause; who at the best knows in the end the triumph of high achievement, and who at the worst, if he fails, at least fails while daring greatly, so that his place shall never be with those cold and timid souls who neither know victory nor defeat.
[Note on the text: in Vidyākara’s compilation the verse ends with “विपुला च लक्ष्मीः” (vipulā ca lakṣmīḥ) instead of “विपुला च पृथ्वी” (vipulā ca pṛthvī), but the actual source work Mālatī-mādhava has the latter, as do all quotations of this verse elsewhere (e.g. the काव्यप्रकाशः of Mammaṭa, the Sahityadarpana of Viśvanātha Kavirāja, the रसार्णवसुधाकरः of श्रीसिंहभूपाल), and that is what Ingalls uses: “For lakṣmīḥ, which utterly destroys the line, read pṛthvi with the printed texts of Māl.” Actually, most quotations have “utpatsyate ‘sti” in place of “utpatsyate tu”: “either will be born, or already exists…”.]
Printing floating-point numbers
Everyone knows that floating-point numbers, being discrete, cannot possibly exactly represent every real number. In particular, the usual binary (IEEE 754) floating point numbers cannot even exactly store all numbers exactly representable in decimal (e.g. 0.3 or 0.1, which are not dyadic rationals).
But what about printing them?
Just because the number stored internally is not 0.1 but the closest approximation to it (say as 0.100000001490116119384765625) doesn’t mean it should be printed as a long string, when “0.1” means exactly the same number.
This is a solved problem since 1990.
TODO: Write rest of this post.
Bryan O’Sullivan (of Real World Haskell fame):
http://www.serpentine.com/blog/2011/06/29/here-be-dragons-advances-in-problems-you-didnt-even-know-you-had/
Steel & White paper How to Print Floating-Point Numbers Accurately: https://lists.nongnu.org/archive/html/gcl-devel/2012-10/pdfkieTlklRzN.pdf
Their retrospective: http://grouper.ieee.org/groups/754/email/pdfq3pavhBfih.pdf
Burger & Dybvig:
Click to access FP-Printing-PLDI96.pdf
Florian Loitsch:
Russ Cox: http://research.swtch.com/ftoa
http://www.ryanjuckett.com/programming/printing-floating-point-numbers/
https://labix.org/python-nicefloat
http://people.csail.mit.edu/jaffer/III/EZFPRW
Edit (Thanks Soma!): Printing Floating-Point Numbers: A Faster, Always Correct Method from POPL’16. Revised to Printing Floating-Point Numbers: An Always Correct Method (see github).
Edit: An example in a programming language. Even though this is a problem solved since 1990 (albeit with developments until this year 2016), even Python until 2.6 had suboptimal printing of floating-point numbers, e.g. it would print float(‘2.2’) as ‘2.2000000000000002’. It was fixed only in Python 2.7. See https://docs.python.org/2/whatsnew/2.7.html#python-3-1-features and https://docs.python.org/3/whatsnew/2.7.html#other-language-changes (specifically https://bugs.python.org/issue7117 and discussion at https://mail.python.org/pipermail/python-dev/2009-October/092958.html).
Kalidasa’s Deepashikha
(Another example of good vs bad translations from Sanskrit. Previously see here and here.)
One of Kālidāsa’s famous similes is in the following verse from the Raghuvaṃśa, in the context of describing the svayaṃvara of Indumatī. The various hopeful suitors of the princess, all kings from different regions, are lined up as she passes them one by one, her friend doing the introductions.
संचारिणी दीपशिखेव रात्रौ यम् यम् व्यतीयाय पतिंवरा सा । नरेन्द्रमार्गाट्ट इव प्रपेदे विवर्णभावम् स स भूमिपालः ॥ ६-६७
saṁcāriṇī dīpa-śikheva rātrau
yam yam vyatīyāya patiṁvarā sā |
narendra-mārga-aṭṭa iva prapede
vivarṇa-bhāvam sa sa bhūmipālaḥ || 6-67
Only today did I discover a decent translation into English. It’s by John Brough (1975/6):
As if a walking lamp-flame in the night
On the king’s highway, flanked with houses tall,
She moved, and lit each prince with hopeful light,
And, passing on, let each to darkness fall.
Every other translation I have seen really falls short. Witness the misunderstandings, and the killing of all feeling.
Here is Ryder (1904), who is usually good:
And every prince rejected while she sought
A husband, darkly frowned, as turrets, bright
One moment with the flame from torches caught,
Frown gloomily again and sink in night.
The idea is there, but requires too much effort to understand.
This is P. de Lacy Johnstone (1902):
Now as the Maid went by, each suitor-King,
Lit for a moment by her dazzling eyes,
Like wayside tower by passing lamp, sank back
In deepest gloom. …
Every king, whom Indumati passed by while choosing her husband, assumed a pale look as the houses on a high way are covered with darkness in the absence of lamps.
Whatsoever king the maiden intent on choosing her husband passed by, like the flame of a moving lamp at night, that same king turned pale, just as a mansion situate on the highway, is shrouded in darkness when left behind (by a moving light).
67. pati.m varA sA= husband, selector, she – she who has come to select her husband, indumati; rAtrau sa.mcAriNI dIpa shikha iva= in night, moving, lamp’s, [glittering] flame, as with; ya.m ya.m= whom, whom; [bhUmi pAlam= king, whomever]; vyatIyAya= passed by; saH saH bhUmipAlaH= he, he, king – such and such a king; narendra mArga= on king’s, way; aTTa= a turret, or a balustrade; iva= like; vi+varNa bhAva.m= without, colour, aspect – they bore a colourless aspect; prapede= [that king] obtained – that king became colourless, he drew blank.
Princess indumati who came to choose her husband then moved like the glittering flame of a lamp on a king’s way, and whichever prince she left behind was suffused with pallor just like a turret or balustrade on the king’s way will be shrouded in darkness and becomes dim when left behind by the moving light on the king’s way. [6-67]
And this is representative of the average quality of Sanskrit-to-English translations, and how much beauty is lost.
Some playing with Python
A long time ago, Diophantus (sort of) discussed integer solutions to the equation
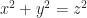
(solutions to this equation are called Pythagorean triples).
Centuries later, in 1637, Fermat made a conjecture (now called Fermat’s Last Theorem, not because he uttered it in his dying breath, but because it was the last one to be proved — in ~1995) that
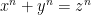
has no positive integer solutions for 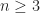
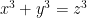


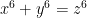
… and so on. An nth power cannot be partitioned into two nth powers.
About a century later, Euler proved the 

has no solutions with 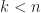
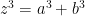
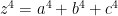
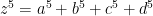
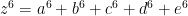
… and so on.
This conjecture stood for about two centuries, until abruptly it was found to be false, by Lander and Parkin who in 1966 simply did a direct search on the fastest (super)computer at the time, and found this counterexample:
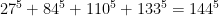
(It is still one of only three examples known, according to Wikipedia.)
Now, how might you find this solution on a computer today?
In his wonderful (as always) post at bit-player, Brian Hayes showed the following code:
import itertools as it
def four_fifths(n):
'''Return smallest positive integers ((a,b,c,d),e) such that
a^5 + b^5 + c^5 + d^5 = e^5; if no such tuple exists
with e < n, return the string 'Failed'.'''
fifths = [x**5 for x in range(n)]
combos = it.combinations_with_replacement(range(1,n), 4)
while True:
try:
cc = combos.next()
cc_sum = sum([fifths[i] for i in cc])
if cc_sum in fifths:
return(cc, fifths.index(cc_sum))
except StopIteration:
return('Failed')
to which, if you add (say) print four_fifths(150) and run it, it returns the correct answer fairly quickly: in about 47 seconds on my laptop.
The if cc_sum in fifths: line inside the loop is an 
import itertools
def find_counterexample(n):
fifth_powers = [x**5 for x in range(n)]
fifth_powers_set = set(fifth_powers)
for xs in itertools.combinations_with_replacement(range(1, n), 4):
xs_sum = sum([fifth_powers[i] for i in xs])
if xs_sum in fifth_powers_set:
return (xs, fifth_powers.index(xs_sum))
return 'Failed'
print find_counterexample(150)
which finishes in about 8.5 seconds.
Great!
But there’s something unsatisfying about this solution, which is that it assumes there’s a solution with all four numbers on the LHS less than 150. After all, changing the function invocation to find_counterexample(145) makes it run a second faster even, but how could we know to do without already knowing the solution? Besides, we don’t have a fixed 8- or 10-second budget; what we’d really like is a program that keeps searching till it finds a solution or we abort it (or it runs out of memory or something), with no other fixed termination condition.
The above program used the given “n” as an upper bound to generate the combinations of 4 numbers; is there a way to generate all combinations when we don’t know an upper bound on them?
Yes! One of the things I learned from Knuth volume 4 is that if you simply write down each combination in descending order and order them lexicographically, the combinations you get for each upper bound are a prefix of the list of the next bigger one, i.e., for any upper bound, all the combinations form a prefix of the same infinite list, which starts as follows (line breaks for clarity):
1111,
2111, 2211, 2221, 2222,
3111, 3211, 3221, 3222, 3311, 3321, 3322, 3331, 3332, 3333,
4111, ...
... 9541, 9542, 9543, 9544, 9551, ... 9555, 9611, ...
There doesn’t seem to be a library function in Python to generate these though, so we can write our own. If we stare at the above list, we can figure out how to generate the next combination from a given one:
- Walk backwards from the end, till you reach the beginning or find an element that’s less than the previous one.
- Increase that element, set all the following elements to 1s, and continue.
We could write, say, the following code for it:
def all_combinations(r):
xs = [1] * r
while True:
yield xs
for i in range(r - 1, 0, -1):
if xs[i] < xs[i - 1]:
break
else:
i = 0
xs[i] += 1
xs[i + 1:] = [1] * (r - i - 1)
(The else block on a for loop is an interesting Python feature: it is executed if the loop wasn’t terminated with break.) We could even hard-code the r=4 case, as we’ll see later below.
For testing whether a given number is a fifth power, we can no longer simply lookup in a fixed precomputed set. We can do a binary search instead:
def is_fifth_power(n):
assert n > 0
lo = 0
hi = n
# Invariant: lo^5 < n <= hi^5
while hi - lo > 1:
mid = lo + (hi - lo) / 2
if mid ** 5 < n:
lo = mid
else:
hi = mid
return hi ** 5 == n
but it turns out that this is slower than one based on looking up in a growing set (as below).
Putting everything together, we can write the following (very C-like) code:
largest_known_fifth_power = (0, 0)
known_fifth_powers = set()
def is_fifth_power(n):
global largest_known_fifth_power
while n > largest_known_fifth_power[0]:
m = largest_known_fifth_power[1] + 1
m5 = m ** 5
largest_known_fifth_power = (m5, m)
known_fifth_powers.add(m5)
return n in known_fifth_powers
def fournums_with_replacement():
(x0, x1, x2, x3) = (1, 1, 1, 1)
while True:
yield (x0, x1, x2, x3)
if x3 < x2:
x3 += 1
continue
x3 = 1
if x2 < x1:
x2 += 1
continue
x2 = 1
if x1 < x0:
x1 += 1
continue
x1 = 1
x0 += 1
continue
if __name__ == '__main__':
tried = 0
for get in fournums_with_replacement():
tried += 1
if (tried % 1000000 == 0):
print tried, 'Trying:', get
rhs = get[0]**5 + get[1]**5 + get[2]**5 + get[3]**5
if is_fifth_power(rhs):
print 'Found:', get, rhs
break
which is both longer and slower (takes about 20 seconds) than the original program, but at least we have the satisfaction that it doesn’t depend on any externally known upper bound.
I originally started writing this post because I wanted to describe some experiments I did with profiling, but it’s late and I’m sleepy so I’ll just mention it.
python -m cProfile euler_conjecture.py
will print relevant output in the terminal:
26916504 function calls in 26.991 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 18.555 18.555 26.991 26.991 euler_conjecture.py:1()
13458164 4.145 0.000 4.145 0.000 euler_conjecture.py:12(fournums_with_replacement)
13458163 4.292 0.000 4.292 0.000 euler_conjecture.py:3(is_fifth_power)
175 0.000 0.000 0.000 0.000 {method 'add' of 'set' objects}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
Another way to view the same thing is to write the profile output to a file and read it with cprofilev:
python -m cProfile -o euler_profile.out euler_conjecture.py cprofilev euler_profile.out
and visit http://localhost:4000 to view it.
Of course, simply translating this code to C++ makes it run much faster:
#include <array>
#include <iostream>
#include <map>
#include <utility>
typedef long long Int;
constexpr Int fifth_power(Int x) { return x * x * x * x * x; }
std::map<Int, int> known_fifth_powers = {{0, 0}};
bool is_fifth_power(Int n) {
while (n > known_fifth_powers.rbegin()->first) {
int m = known_fifth_powers.rbegin()->second + 1;
known_fifth_powers[fifth_power(m)] = m;
}
return known_fifth_powers.count(n);
}
std::array<Int, 4> four_nums() {
static std::array<Int, 4> x = {1, 1, 1, 0};
int i = 3;
while (i > 0 && x[i] == x[i - 1]) --i;
x[i] += 1;
while (++i < 4) x[i] = 1;
return x;
}
std::ostream& operator<<(std::ostream& os, std::array<Int, 4> x) {
os << "(" << x[0] << ", " << x[1] << ", " << x[2] << ", " << x[3] << ")";
return os;
}
int main() {
while (true) {
std::array<Int, 4> get = four_nums();
Int rhs = fifth_power(get[0]) + fifth_power(get[1]) + fifth_power(get[2]) + fifth_power(get[3]);
if (is_fifth_power(rhs)) {
std::cout << "Found: " << get << " " << known_fifth_powers[rhs] << std::endl;
break;
}
}
}
and
clang++ -std=c++11 euler_conjecture.cc && time ./a.out
runs in 2.43s, or 0.36s if compiled with -O2.
But I don’t have a satisfactory answer to how to make our Python program which takes 20 seconds as fast as the 8.5-second known-upper-bound version.
Edit [2015-05-08]: I wrote some benchmarking code to compare all the different “combination” functions.
import itertools
# Copied from the Python documentation
def itertools_equivalent(iterable, r):
pool = tuple(iterable)
n = len(pool)
if not n and r:
return
indices = [0] * r
yield tuple(pool[i] for i in indices)
while True:
for i in reversed(range(r)):
if indices[i] != n - 1:
break
else:
return
indices[i:] = [indices[i] + 1] * (r - i)
yield tuple(pool[i] for i in indices)
# Above function, specialized to first argument being range(1, n)
def itertools_equivalent_specialized(n, r):
indices = [1] * r
yield indices
while True:
for i in reversed(range(r)):
if indices[i] != n - 1:
break
else:
return
indices[i:] = [indices[i] + 1] * (r - i)
yield indices
# Function to generate all combinations of 4 elements
def all_combinations_pythonic(r):
xs = [1] * r
while True:
yield xs
for i in range(r - 1, 0, -1):
if xs[i] < xs[i - 1]:
break
else:
i = 0
xs[i] += 1
xs[i + 1:] = [1] * (r - i - 1)
# Above function, written in a more explicit C-like way
def all_combinations_clike(r):
xs = [1] * r
while True:
yield xs
i = r - 1
while i > 0 and xs[i] == xs[i - 1]:
i -= 1
xs[i] += 1
while i < r - 1:
i += 1
xs[i] = 1
# Above two functions, specialized to r = 4, using tuple over list.
def fournums():
(x0, x1, x2, x3) = (1, 1, 1, 1)
while True:
yield (x0, x1, x2, x3)
if x3 < x2:
x3 += 1
continue
x3 = 1
if x2 < x1:
x2 += 1
continue
x2 = 1
if x1 < x0:
x1 += 1
continue
x1 = 1
x0 += 1
continue
# Benchmarks for all functions defined above (and the library function)
def benchmark_itertools(n):
for xs in itertools.combinations_with_replacement(range(1, n), 4):
if xs[0] >= n:
break
def benchmark_itertools_try(n):
combinations = itertools.combinations_with_replacement(range(1, n), 4)
while True:
try:
xs = combinations.next()
if xs[0] >= n:
break
except StopIteration:
return
def benchmark_itertools_equivalent(n):
for xs in itertools_equivalent(range(1, n), 4):
if xs[0] >= n:
break
def benchmark_itertools_equivalent_specialized(n):
for xs in itertools_equivalent_specialized(n, 4):
if xs[0] >= n:
break
def benchmark_all_combinations_pythonic(n):
for xs in all_combinations_pythonic(4):
if xs[0] >= n:
break
def benchmark_all_combinations_clike(n):
for xs in all_combinations_clike(4):
if xs[0] >= n:
break
def benchmark_fournums(n):
for xs in fournums():
if xs[0] >= n:
break
if __name__ == '__main__':
benchmark_itertools(150)
benchmark_itertools_try(150)
benchmark_itertools_equivalent(150)
benchmark_itertools_equivalent_specialized(150)
benchmark_all_combinations_pythonic(150)
benchmark_all_combinations_clike(150)
benchmark_fournums(150)
As you can see, I chose inside the benchmarking function the same statement that would cause all_combinations to terminate, and have no effect for the other combination functions.
When run with
python -m cProfile benchmark_combinations.pythe results include:
2.817 benchmark_combinations.py:80(benchmark_itertools)
8.583 benchmark_combinations.py:84(benchmark_itertools_try)
126.980 benchmark_combinations.py:93(benchmark_itertools_equivalent)
46.635 benchmark_combinations.py:97(benchmark_itertools_equivalent_specialized)
44.032 benchmark_combinations.py:101(benchmark_all_combinations_pythonic)
18.049 benchmark_combinations.py:105(benchmark_all_combinations_clike)
10.923 benchmark_combinations.py:109(benchmark_fournums)
Lessons:
- Calling
itertools.combinations_with_replacementis by far the fastest, taking about 2.7 seconds. It turns out that it’s written in C, so this would be hard to beat. (Still, writing it in atryblock is seriously bad.) - The “equivalent” Python code from the itertools documentation (
benchmark_itertools_combinations_with_replacment) is about 50x slower. - Gets slightly better when specialized to numbers.
- Simply generating all combinations without an upper bound is actually faster.
- It can be made even faster by writing it in a more C-like way.
- The tuples version with the loop unrolled manually is rather fast when seen in this light, less than 4x slower than the library version.
Boolean blindness
(Just digesting the first page of Google search results.)
One of the lessons from functional programming is to encode as much information as possible into the types. Almost all programmers understand to some extent that types are helpful: they know not to store everything as void* (in C/C++) or as Object (in Java). They even know not to use say double for all numbers, or string for everything (as shell scripts / Tcl do). (This pejoratively called “stringly typed”.)
A corollary, from slide 19 here, is that (when your type system supports richer types) a boolean type is almost always the wrong choice, as it carries too little information.
The name “Boolean blindness” for this seems to have been coined by Dan Licata when taught a course at CMU as a PhD student.
From here (blog post by Robert Harper, his advisor at CMU):
There is no information carried by a Boolean beyond its value, and that’s the rub. As Conor McBride puts it, to make use of a Boolean you have to know its provenance so that you can know what it means.
[…]
Keeping track of this information (or attempting to recover it using any number of program analysis techniques) is notoriously difficult. The only thing you can do with a bit is to branch on it, and pretty soon you’re lost in a thicket of if-then-else’s, and you lose track of what’s what.
[…]The problem is computing the bit in the first place. Having done so, you have blinded yourself by reducing the information you have at hand to a bit, and then trying to recover that information later by remembering the provenance of that bit. An illustrative example was considered in my article on equality:
fun plus x y = if x=Z then y else S(plus (pred x) y)Here we’ve crushed the information we have about x down to one bit, then branched on it, then were forced to recover the information we lost to justify the call to pred, which typically cannot recover the fact that its argument is non-zero and must check for it to be sure. What a mess! Instead, we should write
fun plus x y = case x of Z => y | S(x') => S(plus x' y)No Boolean necessary, and the code is improved as well! In particular, we obtain the predecessor en passant, and have no need to keep track of the provenance of any bit.
Some commenter there says
To the best of my knowledge, Ted Codd was the first to point out, in his relational model, that there is no place for Boolean data types in entity modeling. It is a basic design principle to avoid characterizing data in terms of Boolean values, since there is usually some other piece of information you are forgetting to model, and once you slam a Boolean into your overall data model, it becomes very hard to version towards a more exact model (information loss).
An example from Hacker News (on an unrelated post):
Basically, the idea is that when you branch on a conditional, information is gained. This information may be represented in the type system and used by the compiler to verify safety, or it can be ignored. If it is ignored, the language is said to have “boolean blindness”.
Example:if (ptr == NULL) { ... a ... } else { ... b ... }In branch a and branch b, different invariants about ptr hold. But the language/compiler are not verifying any of these invariants.
Instead, consider:
data Maybe a = Nothing | Just a
This defines a type “Maybe”, parameterized by a type variable “a”, and it defines two “data constructors” that can make a Maybe value: “Nothing” which contains nothing, and “Just” which contains a value of type “a” inside it.
This is known as a “sum” type, because the possible values of the type are the sum of all data constructor values.
We could still use this sum data-type in a boolean-blind way:if isJust mx then .. use fromJust mx .. -- UNSAFE! else .. can't use content of mx ..However, using pattern-matching, we can use it in a safe way. Assume “mx” is of type “Maybe a”:
case mx of Nothing -> ... There is no value of type "a" in our scope Just x -> ... "x" of type "a" is now available in our scope!
So when we branch on the two possible cases for the “mx” type, we gain new type information that gets put into our scope.
“Maybe” is of course a simple example, but this is also applicable for any sum type at all.
Another from notes of someone called HXA7241:
A nullable pointer has two ‘parts’: null, and all-other-values. These can be got at with a simple if-else conditional:
if p is not null then ... else ... end. And there is still nothing wrong with that. The problem arrives when you want to handle the parts – and you lack a good type system. What do you do with the non-null pointer value? You just have to put it back into a pointer again – a nullable pointer: which is what you started with. So where has what you did with the test been captured? Nowhere. When you handle that intended part elsewhere you have to do the test again and again.
A Reddit discussion: Don Stewart says
Not strongly typed, richly typed. Where evidence isn’t thrown away. Agda is about the closest thing to this we have.
Relation to “object-oriented programming”
There’s also a good (and unintentionally revealing) example there by user munificent. Consider Harper’s example, which in more explicit Haskell could be:
data Num = Zero | Succ Num
plus :: Num -> Num -> Num
plus Zero y = y
plus (Succ x) y = Succ (plus x y)
We might write it in Java as the following:
interface Num {}
class Zero implements Num {}
class Succ implements Num {
public Succ(Num pred) {
this.pred = pred;
}
public final Num pred;
}
Num plus(Num x, Num y) {
if (x instanceof Succ) { // (1)
Succ xAsSucc = (Succ)x; // (2)
return new Succ(plus(xAsSucc.pred, y));
} else {
return y;
}
}
Here instanceof returns a boolean (comment (1)), but doesn’t carry with it any information about what that boolean represents (namely that x is an instance of Succ) so when we get to the next line (2) we’re forced to do an unsafe cast. As programmers, we know it’s safe from context, but the compiler doesn’t.
There is a way in Java of avoiding this situation (where the programmer has context the compiler doesn’t):
interface Num {
Num plus(Num other);
}
class Zero implements Num {
public Num plus(Num other) {
return other;
}
}
class Succ implements Num {
public Succ(Num pred) {
this.pred = pred;
}
public Num plus(Num other) {
return new Succ(pred.plus(y));
}
public final Num pred;
}
But see what has happened (by user aaronia):
There’s a rub though — in your first code snippet, “plus” was written as a non-member function; anyone can write it as a stand alone library. It was modular. But, as you demonstrated, it had the redundant type check.
However, your second code snippet has lost this modularity. You had to add new methods to the Num data type.
I think this is the pitfall of Object-Oriented Programming (which is like “Pants-Oriented Clothing”): objects can talk about themselves, but it’s harder to talk about objects.
If you want to write a function that does similar things for a bunch of types, you have to write similar function definitions in all those different classes. These function definitions do not stay together, so there is no way of knowing or ensuring that they are similar.
C++ vs Java terminology glossary
E.g. there is no such thing as a “method” in C++. As far as the C++ standard is concerned, functions inside classes are always called “member functions”.
Here is a handout from this course (taught by, AFAICT, Jeffrey S. Leon) that helps me understand the Java people.
The “most natural” definition of the div and mod functions
[incomplete: must add examples and more discussion]
Most programming languages include a “remainder” or “modulo” function, and also an integer division (“quotient”) function. Given two integers 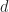

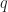
For positive 
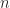
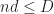
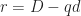
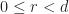
What should we do when, as frequently happens,
For negative 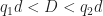
(1) Set
(2) Set
There are very good reasons why (1) is preferable to (2): it ensures that the function 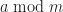

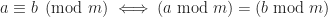
And indeed that is what the more recent programming languages do. There is a table on Wikipedia: C, C++, Java, Go(!), OCaml(!), PHP, all have the “bad” behaviour, while Maple, Mathematica, Microsoft Excel, Perl, Python, Ruby have the “good” behaviour. Some languages have separate functions for both behaviours (e.g. Haskell has quotRem and divMod functions, similarly Common Lisp, Fortran, MATLAB).
There’s also the question of what to do when 
These are elaborated in The Euclidean Definition of the Functions div and mod by Raymond T. Boute, ACM Transactions on Programming Languages and Systems, Vol 14, No. 2, April 1992.
Danda-padyam
Viṣṇu, appearing before Bali as Vāmana, transformed into Trivikrama, filling the universe, covering all the earth and the heavens in two steps.
The verse that opens the Pūrva-pīṭhikā of Daṇḍin’s Daśakumāracarita plays on this imagination, and on the word daṇda / daṇḍin. Here’s the verse (in Sragdharā metre of pattern GGGGLGG—LLLLLLG—GLGGLGG):
May the leg of Trivikrama,
pole for the parasol that is the universe,
stem of the lotus that is Brahma’s seat,
mast of the ship that is the earth,
rod of the streaming banner that is the river of the Gods,
axle-rod around which the zodiac turns,
pillar of victory over the three worlds,
rod of death for the enemies of the Gods,
favour you with blessings.brahmāṇḍa-cchatradaṇḍaḥ śata-dhṛti-bhavan’-âmbhoruho nāla-daṇḍaḥ
kṣoṇī-nau-kūpa-daṇḍaḥ kṣarad-amara-sarit-paṭṭikā-ketu-daṇḍaḥ /
jyotiścakr’-âkṣa-daṇḍas tribhuvana-vijaya-stambha-daṇḍo ‘ṅghri-daṇḍaḥ
śreyas traivikramas te vitaratu vibudha-dveṣiṇāṃ kāla-daṇḍaḥ //ब्रह्माण्डच्छत्रदण्डः शतधृतिभवनाम्भोरुहो नालदण्डः क्षोणीनौकूपदण्डः क्षरदमरसरित्पट्टिकाकेतुदण्डः । ज्योतिश्चक्राक्षदण्डस्त्रिभुवनविजयस्तम्भदण्डोऽङ्घ्रिदण्डः श्रेयस्त्रैविक्रमस्ते वितरतु विबुधद्वेषिणां कालदण्डः ॥
[The Mānasataraṃgiṇī-kāra, agreeing with Santillana and von Dechend the authors of Hamlet’s Mill, considers the “pole” or “axis” motif central to the conception of Vishnu (e.g. matsya‘s horn, Mount Meru as the rod on kūrma, nṛsiṃha from the pillar, etc.: see here), sees much more depth in this poem, and that Daṇḍin was remembering this old motif.]
The translation above is mildly modified from that of Isabelle Onians in her translation (“What Ten Young Men Did”) of the Daśa-kumāra-carita, published by the Clay Sanskrit Library:
Pole for the parasol-shell that is Brahma’s cosmic egg,
Stem for Brahma’s lotus seat,
Mast for the ship that is the earth,
Rod for the banner that is the rushing immortal river Ganges,
Axle rod for the rotating zodiac,
Pillar of victory over the three worlds—
May Vishnu’s leg favor you with blessings—
Staff that is the leg of him who as Trivikrama reclaimed those three worlds in three steps,
Rod of time, death itself, for the demon enemies of the gods.
Ryder, in his translation (“The Ten Princes”), takes some liberties and manages verse in couplets:
May everlasting joy be thine,
Conferred by Vishnu’s foot divine,Which, when it trod the devils flat,
Became the staff of this and that:The staff around which is unfurled,
The sunshade of the living world;The flagstaff for the silken gleam
Of sacred Ganges’ deathless stream;The mast of earth’s far-driven ship,
Round which the stars (as axis) dip;The lotus stalk of Brahma’s shrine;
The fulcrumed staff of life divine.
For another verse that fully gets into this “filling the universe” spirit, see The dance of the bhairava on manasa-taramgini.
Sanskrit and German
[Originally posted to linguistics.stackexchange.com as an answer to a question by user Manishearth, who asked: “I’ve heard many times that learning German is easier for those who speak Sanskrit, and vice versa. Is there any linguistic basis for this? What similarities exist between the two languages that may be able to explain this?”]
This is an answer not to the part about whether it is easier to learn German after Sanskrit (I don’t know), but rather, a few more assorted points re. “What similarities exist between the two languages”, or even more generally, “Why would people make such a claim?”
As Cerberus [another user] noted, most of these claims come from people whose familiarity, outside of Indian languages, is with mainly English, and perhaps a bit of French (or rarely, Spanish or Italian). So even though many similarities noted between Sanskrit and German are in fact those shared by many members of the Indo-European family, the claim just means that among the few languages considered, German’s similarities are remarkable.
[My background: I have a reasonable familiarity with Sanskrit; not so much with German. For impressions about German I’ll rely on the Wikipedia articles, and, (don’t lynch me) Mark Twain’s humorous essay The Awful German Language — of course I know it’s unfair and not a work of linguistics, but as examples of what the average English speaker might find unusual in German, it is a useful document.]
With that said, some similarities:
Cases
German apparently has four cases; Sanskrit has eight cases (traditional Sanskrit grammar counts seven, not counting the vocative as distinct). As Cerberus [another user] notes, “Sanskrit and German have several functional cases, whereas French/Spanish/Italian/Portuguese/Dutch/English/etc. do not. Those are the languages one might be inclined to compare Sanskrit with”.
Compound words
Although English does have short compound words (like bluebird, horseshoe, paperback or pickpocket), German has a reputation for long compound words. (Twain complains that the average German sentence “is built mainly of compound words constructed by the writer on the spot, and not to be found in any dictionary — six or seven words compacted into one, without joint or seam — that is, without hyphens”) He mentions Stadtverordnetenversammlungen and Generalstaatsverordnetenversammlungen; Wikipedia mentions Rindfleischetikettierungsüberwachungsaufgabenübertragungsgesetz and Donaudampfschiffahrtselektrizitätenhauptbetriebswerkbauunterbeamtengesellschaft. But these are nothing compared to the words one routinely finds in ornate Sanskrit prose. See for example this post. Sanskrit like German allows compounds of arbitrary length, and compounds made of four or five words are routinely found in even the most common Sanskrit texts.
Verb appearing late
It appears that German words tend to come later in the sentence than English speakers are comfortable with. I notice questions on this SE showing that German has V2 word order, not SOV. However, many English speakers seem to find late verbs in German worth remarking on. One of my favourite sentences from Hofstadter goes
“The proverbial German phenomenon of the “verb-at-the-end”, about which droll tales of absentminded professors who would begin a sentence, ramble on for an entire lecture, and then finish up by rattling off a string of verbs by which their audience, for whom the stack had long since lost its coherence, would be totally nonplussed, are told, is an excellent example of linguistic pushing and popping.”
Twain too, says “the reader is left to flounder through to the remote verb” and gives the analogy of
“But when he, upon the street, the (in-satin-and-silk-covered-now-very-unconstrained-after-the-newest-fashioned-dressed) government counselor’s wife met,”
and also
“In the daybeforeyesterdayshortlyaftereleveno’clock Night, the inthistownstandingtavern called `The Wagoner’ was downburnt. When the fire to the onthedownburninghouseresting Stork’s Nest reached, flew the parent Storks away. But when the bytheraging, firesurrounded Nest itself caught Fire, straightway plunged the quickreturning Mother-stork into the Flames and died, her Wings over her young ones outspread.”
Well, this is exactly typical Sanskrit writing. Those sentences might have been translated verbatim from a Sanskrit text. Sanskrit technically has free word order (i.e., words can be put in any order), and this is made much use of in verse, but in prose, usage tends to be SOV.
Of Sanskrit’s greatest prose work, Kādambarī, someone named Albrecht Weber wrote in 1853 that in it,
“the verb is kept back to the second, third, fourth, nay, once to the sixth page, and all the interval is filled with epithets and epithets to these epithets: moreover these epithets frequently consist of compounds extending over more than one line; in short, Bāṇa’s prose is an Indian wood, where all progress is rendered impossible by the undergrowth until the traveller cuts out a path for himself, and where, even then, he has to reckon with malicious wild beasts in the shape of unknown words that affright him.” (“…ein wahrer indischer Wald…”)
(This is unfair criticism: personally, I have been lately reading the Kādambarī with the help of friends more experienced in Sanskrit, and I must say the style is truly enjoyable.) Now, the fact that this was a German Indologist writing for the Journal of the German Oriental Society somewhat goes against the claim of Sanskrit and German being similar. But one could say: for someone familiar with Sanskrit’s long compounds and late verbs that even Germans find difficult, the same features in German will pose little difficulty.
Adjectives decline like nouns
In Sanskrit, as it appears to be in German, an adjective takes the gender, case, and number of whatever it is describing. (Twain: “would rather decline two drinks than one German adjective”)
Gender of nouns has to be learned
By and large, it is so in Sanskrit as well. Twain notes that in German “a tree is male, its buds are female, its leaves are neuter; horses are sexless, dogs are male, cats are female — tomcats included, of course; a person’s mouth, neck, bosom, elbows, fingers, nails, feet, and body are of the male sex, and his head is male or neuter according to the word selected to signify it, and not according to the sex of the individual who wears it — for in Germany all the women either male heads or sexless ones; a person’s nose, lips, shoulders, breast, hands, and toes are of the female sex; and his hair, ears, eyes, chin, legs, knees, heart, and conscience haven’t any sex at all”. (He goes on to write a “Tale of the Fishwife and its Sad Fate.”) It does not seem quite so bad in Sanskrit, but yes, gender of words needs to be learned. (In Sanskrit there exists a word for “wife” in each of the three genders.) However this is a feature common to many languages (including, say, languages like Hindi or French that have only two genders) so I shouldn’t list it among similarities.
Spelling
This is something quite trivial, and linguists often don’t even consider orthography a part of the language proper, but spelling seems to be a pretty big deal to Indians learning other languages. The writing systems of most Indian languages are phonetic, in the sense that the spelling deterministically reflects the pronunciation and vice-versa. There are no silent letters, no wondering about a word spelled in a particular way is pronounced. Indian learners of English often complain about the ad-hoc inconsistent spelling of English; it seems a bigger deal than it should be. From this point of view, the fact that it is claimed that for German, “After one short lesson in the alphabet, the student can tell how any German word is pronounced without having to ask” means that that aspect of German is easier to learn.
The harmony of sound and sense
This is extremely subjective and will be controversial, and perhaps I will seem biased, but to me, in Sanskrit, it seems possible to pick words whose sounds match the desired feeling, better than in other languages. I have seen people who knew many languages say the same thing, and also Western translators from Sanskrit etc., so it is interesting for me to see Twain make a similar remark about German. Anyway, this is subjective, so I’ll not dwell on this much.
Non-similarities
There are of course many; e.g. Sanskrit does not have articles (the, etc.) unlike German. It also has very few prepositions (has only a few ones like “without”, “with”, “before”), as the work of prepositions like “to”, “from”, or “by” is handled by case. The difficulty of German prepositions does not seem to be present in Sanskrit.
TL;DR version
Some alleged difficulties of learning German, such as cases, long compounds, and word order, are present to a far greater extent in Sanskrit, so in principle someone who knows Sanskrit may be able to pick them up more easily than someone trying to learn German without this knowledge. However, this may not be saying anything more than that knowing one language helps you learn others.
Colliding balls approximate pi
Found via G+, a new physical experiment that approximates 
Roughly, the amazing discovery of Gregory Galperin is this: When a ball of mass 
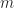
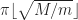
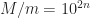
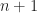
Here’s a video demonstrating the fact for 
The NYT post says how this discovery came about:
Dr. Galperin’s approach was also geometric but very different (using an unfolding geodesic), building on prior related insights. Dr. Galperin, who studied under well-known Russian mathematician Andrei Kolmogorov, had recently written (with Yakov Sinai) extensively on ball collisions, realized just before a talk in 1995 that a plot of the ball positions of a pair of colliding balls could be used to determine pi. (When he mentioned this insight in the talk, no one in the audience believed him.) This finding was ultimately published as “Playing Pool With Pi” in a 2003 issue of Regular and Chaotic Dynamics.
The paper, Playing Pool With π (The number π from a billiard point of view) is very readable. The post has, despite a “solution” section, essentially no explanation, but the two comments by Dave in the comments section explain it clearly. And a reader sent in a cleaned-up version of that too: here, by Benjamin Wearn who teaches physics at Fieldston School.
Now someone needs to make a simulation / animation graphing the two balls in phase space of momentum. :-)
I’d done something a while ago, to illustrate The Orbit of the Moon around the Sun is Convex!, here. Probably need to re-learn all that JavaScript stuff, to make one for this. Leaving this post here as a placeholder.
Or maybe someone has done it already?

,_Professor_of_Astronomy,_teaching_a_class_at_Queen%27s_College,_Varanasi.jpg){kind=link}